Pipeline Performance Considerations管道性能注意事项
Similar to any programming language, there is a downside if you prematurely optimise an aggregation pipeline. 与任何编程语言类似,如果过早地优化聚合管道,也会有不利影响。You risk producing an over-complicated solution that doesn't address the performance challenges that will manifest. 您可能会产生一个过于复杂的解决方案,而该解决方案无法解决将出现的性能挑战。As described in the previous chapter, Using Explain Plans, the tool you should use to identify opportunities for optimisation is the explain plan. 如前一章“使用解释计划”所述,您应该使用解释计划来确定优化机会。You will typically use the explain plan during the final stages of your pipeline's development once it is functionally correct.一旦功能正确,您通常会在管道开发的最后阶段使用解释计划。
With all that said, it can still help you to be aware of some guiding principles regarding performance whilst you are prototyping a pipeline. 尽管如此,它仍然可以帮助您在制作管道原型时了解一些有关性能的指导原则。Critically, such guiding principles will be invaluable to you once the aggregation's explain plan is analysed and if it shows that the current pipeline is sub-optimal.至关重要的是,一旦分析了聚合的解释计划,并且表明当前的管道是次优的,这些指导原则将对您非常宝贵。
This chapter outlines three crucial tips to assist you when creating and tuning an aggregation pipeline. 本章概述了在创建和调优聚合管道时提供帮助的三个关键提示。For sizeable data sets, adopting these principles may mean the difference between aggregations completing in a few seconds versus minutes, hours or even longer.对于相当大的数据集,采用这些原则可能意味着在几秒钟内完成的聚合与几分钟、几小时甚至更长时间内完成的汇总之间的差异。
1. Be Cognizant Of Streaming Vs Blocking Stages Ordering注意流媒体与阻塞阶段的排序
When executing an aggregation pipeline, the database engine pulls batches of records from the initial query cursor generated against the source collection. 执行聚合管道时,数据库引擎会从针对源集合生成的初始查询游标中提取一批记录。The database engine then attempts to stream each batch through the aggregation pipeline stages. 然后,数据库引擎尝试通过聚合管道阶段对每个批进行流式传输。For most types of stages, referred to as streaming stages, the database engine will take the processed batch from one stage and immediately stream it into the next part of the pipeline. 对于大多数类型的阶段(称为流阶段),数据库引擎将从一个阶段获取处理后的批,并立即将其流式传输到管道的下一部分。It will do this without waiting for all the other batches to arrive at the prior stage. 它将在不等待所有其他批次到达前一阶段的情况下完成此操作。However, two types of stages must block and wait for all batches to arrive and accumulate together at that stage. 然而,两种类型的阶段必须阻塞并等待所有批次到达,并在该阶段一起累积。These two stages are referred to as blocking stages and specifically, the two types of stages that block are:这两个阶段被称为阻塞阶段,具体而言,阻塞的两种类型的阶段是:
$sort$group*
*
actually when stating实际上,在陈述$group, this also includes other less frequently used "grouping" stages too, specifically:$group时,它还包括其他不太常用的“分组”阶段,特别是:$bucket,$bucketAuto,$count,$sortByCount&$facet(it's a stretch to call(将$faceta group stage, but in the context of this topic, it's best to think of it that way)$facet称为小组阶段是一种延伸,但在本主题的上下文中,最好这样想)
The diagram below highlights the nature of streaming and blocking stages. 下图突出显示了流和阻塞阶段的性质。Streaming stages allow batches to be processed and then passed through without waiting. 流阶段允许处理批处理,然后无需等待即可通过。Blocking stages wait for the whole of the input data set to arrive and accumulate before processing all this data together.阻塞阶段等待整个输入数据集到达并累积,然后再一起处理所有这些数据。
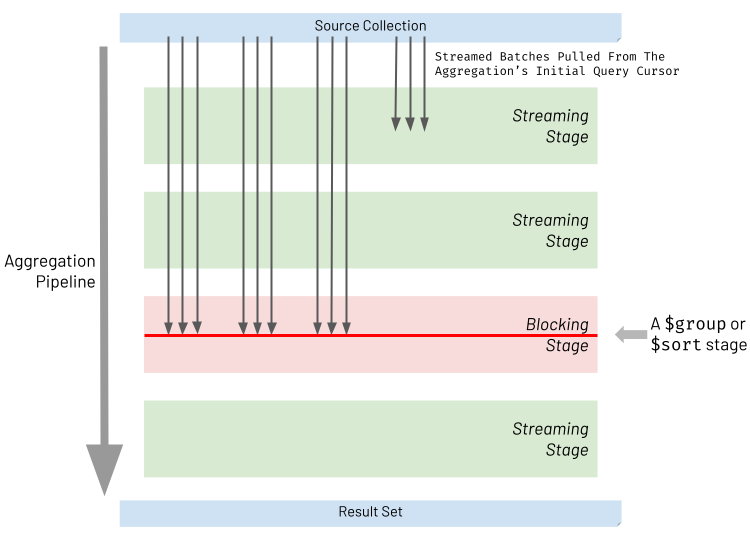
When considering 当考虑$sort and $group stages, it becomes evident why they have to block. $sort和$group阶段时,它们必须阻塞的原因就显而易见了。The following examples illustrate why this is the case:以下示例说明了为什么会出现这种情况:
-
$sortblocking example阻塞示例: A pipeline must sort people in ascending order of age.:管道必须按年龄升序对人员进行排序。If the stage only sorts each batch's content before passing the batch on to the pipeline's result, only individual batches of output records are sorted by age but not the whole result set.如果阶段在将批次传递到管道的结果之前只对每个批次的内容进行排序,则只有个别批次的输出记录按年龄排序,而不是按整个结果集排序。 -
$groupblocking example阻塞示例: A pipeline must group employees by one of two work departments (either the sales or manufacturing departments).:一个管道必须按两个工作部门之一(销售或制造部门)对员工进行分组。If the stage only groups employees for a batch, before passing it on, the final result contains the work departments repeated multiple times.如果该阶段只对一批员工进行分组,则在传递之前,最终结果包含重复多次的工作部门。Each duplicate department consists of some but not all of its employees.每个重复的部门都由部分但不是全部员工组成。
These often unavoidable blocking stages don't just increase aggregation execution time by reducing concurrency. 这些通常不可避免的阻塞阶段不仅通过减少并发来增加聚合执行时间。If used without careful forethought, the throughput and latency of a pipeline will slow dramatically due to significantly increased memory consumption. 如果在没有仔细考虑的情况下使用,由于内存消耗的显著增加,管道的吞吐量和延迟将显著降低。The following sub-sections explore why this occurs and tactics to mitigate this.以下小节探讨了发生这种情况的原因以及缓解这种情况的策略。
$sort Memory Consumption And Mitigation$sort内存消耗和缓解
$sort Memory Consumption And MitigationUsed naïvely, a 使用naïvely时,$sort stage will need to see all the input records at once, and so the host server must have enough capacity to hold all the input data in memory. $sort阶段需要同时查看所有输入记录,因此主机服务器必须有足够的容量将所有输入数据保存在内存中。The amount of memory required depends heavily on the initial data size and the degree to which the prior stages can reduce the size. 所需的内存量在很大程度上取决于初始数据大小和先前阶段可以减少大小的程度。Also, multiple instances of the aggregation pipeline may be in-flight at any one time, in addition to other database workloads. 此外,除了其他数据库工作负载之外,聚合管道的多个实例也可以在任何时候运行。These all compete for the same finite memory. Suppose the source data set is many gigabytes or even terabytes in size, and earlier pipeline stages have not reduced this size significantly. 这些都在争夺相同的有限内存。假设源数据集的大小是许多GB甚至TB,而早期的管道阶段并没有显著减少这个大小。It will be unlikely that the host machine has sufficient memory to support the pipeline's blocking 主机不太可能有足够的内存来支持管道的阻塞$sort stage. $sort阶段。Therefore, MongoDB enforces that every blocking stage is limited to 100 MB of consumed RAM. The database throws an error if it exceeds this limit.因此,MongoDB强制要求每个阻塞阶段的RAM消耗限制在100MB以内。如果超过此限制,数据库将抛出错误。
To avoid the memory limit obstacle, you can set the 为了避免内存限制的障碍,您可以为处理大型结果数据集的整体聚合设置allowDiskUse:true option for the overall aggregation for handling large result data sets. allowDiskUse:true选项。Consequently, the pipeline's sort operation spills to disk if required, and the 100 MB limit no longer constrains the pipeline. 因此,如果需要,管道的排序操作会溢出到磁盘,并且100MB的限制不再约束管道。However, the sacrifice here is significantly higher latency, and the execution time is likely to increase by orders of magnitude.然而,这里的牺牲是显著更高的延迟,并且执行时间可能会增加几个数量级。
To circumvent the aggregation needing to manifest the whole data set in memory or overspill to disk, attempt to refactor your pipeline to incorporate one of the following approaches (in order of most effective first):为了避免聚合需要在内存中显示整个数据集或溢出到磁盘,请尝试重构您的管道,以采用以下方法之一(按最有效的顺序排列):
-
Use Index Sort.使用索引排序。If the如果$sortstage does not depend on a$unwind,$groupor$projectstage preceding it, move the$sortstage to near the start of your pipeline to target an index for the sort.$sort阶段不依赖于它之前的$unwind、$group或$project阶段,请将$sort舞台移动到管道起点附近,以确定排序的索引。The aggregation runtime does not need to perform an expensive in-memory sort operation as a result.因此,聚合运行时不需要执行昂贵的内存内排序操作。The$sortstage won't necessarily be the first stage in your pipeline because there may also be a$matchstage that takes advantage of the same index.$sort阶段不一定是管道中的第一个阶段,因为可能还有一个$match阶段可以利用相同的索引。Always inspect the explain plan to ensure you are inducing the intended behaviour.始终检查解释计划,以确保您正在诱导预期行为。 -
Use Limit With Sort.使用排序限制。If you only need the first subset of records from the sorted set of data, add a如果您只需要排序数据集中的第一个子集记录,请在$limitstage directly after the$sortstage, limiting the results to the fixed amount you require (e.g. 10).$sort阶段之后直接添加$limit阶段,将结果限制在所需的固定数量(例如10)。At runtime, the aggregation engine will collapse the在运行时,聚合引擎将把$sortand$limitinto a single special internal sort stage which performs both actions together.$sort和$limit分解为一个特殊的内部排序阶段,该阶段同时执行这两个操作。The in-flight sort process only has to track the ten records in memory, which currently satisfy the executing sort/limit rule.飞行中的排序过程只需要跟踪内存中的十条记录,这些记录当前满足正在执行的排序/限制规则。It does not have to hold the whole data set in memory to execute the sort successfully.它不必将整个数据集保存在内存中即可成功执行排序。 -
Reduce Records To Sort.减少要排序的记录。Move the将$sortstage to as late as possible in your pipeline and ensure earlier stages significantly reduce the number of records streaming into this late blocking$sortstage.$sort阶段移到管道中尽可能晚的阶段,并确保早期阶段显著减少流到此后期阻塞$sort的记录数量。This blocking stage will have fewer records to process and less thirst for RAM.这个阻塞阶段将减少需要处理的记录,减少对RAM的渴望。
$group Memory Consumption And Mitigation内存消耗和缓解
Like the 与$sort stage, the $group stage has the potential to consume a large amount of memory. $sort阶段一样,$group阶段有可能消耗大量内存。The aggregation pipeline's 100 MB RAM limit for blocking stages applies equally to the 聚合管道对阻塞阶段的100MB RAM限制同样适用于$group stage because it will potentially pressure the host's memory capacity. $group阶段,因为这可能会给主机的内存容量带来压力。As with sorting, you can use the pipeline's 与排序一样,您可以使用管道的allowDiskUse:true option to avoid this limit for heavyweight grouping operations, but with the same downsides.allowDiskUse:true选项来避免重量级分组操作的限制,但也有同样的缺点。
In reality, most grouping scenarios focus on accumulating summary data such as totals, counts, averages, highs and lows, and not itemised data. 事实上,大多数分组场景都侧重于累积汇总数据,如总数、计数、平均值、高点和低点,而不是逐项列出的数据。In these situations, considerably reduced result data sets are produced, requiring far less processing memory than a 在这些情况下,生成的结果数据集大大减少,所需的处理内存远少于$sort stage. $sort阶段。Contrary to many sorting scenarios, grouping operations will typically demand a fraction of the host's RAM.与许多排序场景相反,分组操作通常只需要主机RAM的一小部分。
To ensure you avoid excessive memory consumption when you are looking to use a 为了确保在使用$group stage, adopt the following principles:$group阶段时避免过度消耗内存,请采用以下原则:
-
Avoid Unnecessary Grouping.避免不必要的分组。This chapter covers this recommendation in far greater detail in the section 2. Avoid Unwinding & Regrouping Documents Just To Process Array Elements.本章在第2节:避免为了处理数组元素而对文档展开和重新分组中更详细地介绍了这一建议。 -
Group Summary Data Only.仅限组摘要数据。If the use case permits it, use the group stage to accumulate things like totals, counts and summary roll-ups only, rather than holding all the raw data of each record belonging to a group.如果用例允许,请使用组阶段仅累积总计、计数和汇总等内容,而不是保存属于一个组的每个记录的所有原始数据。The Aggregation Framework provides a robust set of accumulator operators to help you achieve this inside a聚合框架提供了一组强大的累加器运算符,以帮助您在$groupstage.$group阶段内实现这一点。
2. Avoid Unwinding & Regrouping Documents Just To Process Array Elements避免仅为处理数组元素而展开和重新分组文档
Sometimes, you need an aggregation pipeline to mutate or reduce an array field's content for each record. For example:有时,您需要一个聚合管道来更改或减少每个记录的数组字段内容。例如:
You may need to add together all the values in the array into a total field您可能需要将数组中的所有值相加到一个合计字段中You may need to retain the first and last elements of the array only您可能只需要保留数组的第一个和最后一个元素You may need to retain only one recurring field for each sub-document in the array数组中的每个子文档可能只需要保留一个重复出现的字段- ...
or numerous other array "reduction" scenarios或许多其他数组“缩减”场景
To bring this to life, imagine a retail 为了实现这一点,想象一个零售orders collection where each document contains an array of products purchased as part of the order, as shown in the example below:orders集合,其中每个文档都包含作为订单一部分购买的一系列产品,如下面的示例所示:
[
{
_id: 1197372932325,
products: [
{
prod_id: 'abc12345',
name: 'Asus Laptop',
price: NumberDecimal('429.99')
}
]
},
{
_id: 4433997244387,
products: [
{
prod_id: 'def45678',
name: 'Karcher Hose Set',
price: NumberDecimal('23.43')
},
{
prod_id: 'jkl77336',
name: 'Picky Pencil Sharpener',
price: NumberDecimal('0.67')
},
{
prod_id: 'xyz11228',
name: 'Russell Hobbs Chrome Kettle',
price: NumberDecimal('15.76')
}
]
}
]The retailer wants to see a report of all the orders but only containing the expensive products purchased by customers (e.g. having just products priced greater than 15 dollars). 零售商希望看到所有订单的报告,但只包含客户购买的昂贵产品(例如,只有价格超过15美元的产品)。Consequently, an aggregation is required to filter out the inexpensive product items of each order's array. 因此,需要进行聚合以筛选出每个订单数组中的廉价产品项。The desired aggregation output might be:所需的聚合输出可能是:
[
{
_id: 1197372932325,
products: [
{
prod_id: 'abc12345',
name: 'Asus Laptop',
price: NumberDecimal('429.99')
}
]
},
{
_id: 4433997244387,
products: [
{
prod_id: 'def45678',
name: 'Karcher Hose Set',
price: NumberDecimal('23.43')
},
{
prod_id: 'xyz11228',
name: 'Russell Hobbs Chrome Kettle',
price: NumberDecimal('15.76')
}
]
}
]Notice order 注意订单4433997244387 now only shows two products and is missing the inexpensive product.44339997244387现在只显示两种产品,缺少便宜的产品。
One naïve way of achieving this transformation is to unwind the products array of each order document to produce an intermediate set of individual product records. 实现这种转换的一种简单方法是展开每个订单文档的产品数组,以生成一组中间的单个产品记录。These records can then be matched to retain products priced greater than 15 dollars. 然后可以匹配这些记录以保留价格大于15美元的产品。Finally, the products can be grouped back together again by each order's 最后,可以通过每个订单的_id field. _id字段将产品重新分组在一起。The required pipeline to achieve this is below:实现这一目标所需的管道如下:
// SUBOPTIMAL
var pipeline = [
// Unpack each product from the each order's product as a new separate record将每个订单产品中的每个产品拆开包装,作为一个新的单独记录
{"$unwind": {
"path": "$products",
}},
// Match only products valued over 15.00
{"$match": {
"products.price": {
"$gt": NumberDecimal("15.00"),
},
}},
// Group by product type
{"$group": {
"_id": "$_id",
"products": {"$push": "$products"},
}},
];This pipeline is suboptimal because a 这个管道是次优的,因为引入了$group stage has been introduced, which is a blocking stage, as outlined earlier in this chapter. $group阶段,这是一个阻塞阶段,如本章前面所述。Both memory consumption and execution time will increase significantly, which could be fatal for a large input data set. 内存消耗和执行时间都将显著增加,这对于大型输入数据集来说可能是致命的。There is a far better alternative by using one of the Array Operators instead. 有一个更好的替代方法,可以使用其中一个数组运算符。Array Operators are sometimes less intuitive to code, but they avoid introducing a blocking stage into the pipeline. 数组运算符有时对代码不太直观,但它们避免在管道中引入阻塞阶段。Consequently, they are significantly more efficient, especially for large data sets. 因此,它们的效率明显更高,尤其是对于大型数据集。Shown below is a far more economical pipeline, using the 下面显示的是一个更经济的管道,使用$filter array operator, rather than the $unwind/$match/$group combination, to produce the same outcome:$filter数组运算符,而不是$unwind/$match/$group组合,可以产生相同的结果:
// OPTIMAL
var pipeline = [
// Filter out products valued 15.00 or less
{"$set": {
"products": {
"$filter": {
"input": "$products",
"as": "product",
"cond": {"$gt": ["$$product.price", NumberDecimal("15.00")]},
}
},
}},
];Unlike the suboptimal pipeline, the optimal pipeline will include "empty orders" in the results for those orders that contained only inexpensive items. 与次优管道不同,对于那些只包含廉价商品的订单,最优管道将在结果中包括“空订单”。If this is a problem, you can include a simple 如果这是一个问题,可以在最佳管道的开头包含一个简单的$match stage at the start of the optimal pipeline with the same content as the $match stage shown in the suboptimal example.$match阶段,其内容与次优示例中显示的$match阶段相同。
To reiterate, there should never be the need to use an 重申一下,在聚合管道中永远不应该使用$unwind/$group combination in an aggregation pipeline to transform an array field's elements for each document in isolation. $unwind/$group组合来为每个文档单独转换数组字段的元素。One way to recognise this anti-pattern is if your pipeline contains a 识别这种反模式的一种方法是,如果您的管道在$group on a $_id field. $字段上包含_id$group。Instead, use Array Operators to avoid introducing a blocking stage. 相反,请使用数组运算符来避免引入阻塞阶段。Otherwise, you will suffer a magnitude increase in execution time when the blocking group stage in your pipeline handles more than 100 MB of in-flight data. 否则,当管道中的阻塞组阶段处理超过100MB的运行中数据时,执行时间将大幅增加。Adopting this best practice may mean the difference between achieving the required business outcome and abandoning the whole task as unachievable.采用这种最佳实践可能意味着实现所需的业务结果和放弃无法实现的整个任务之间的区别。
The primary use of an $unwind/$group combination is to correlate patterns across many records' arrays rather than transforming the content within each input record's array only. $unwind/$group组合的主要用途是在许多记录的数组中关联模式,而不是仅转换每个输入记录的数组内的内容。For an illustration of an appropriate use of 有关$unwind/$group refer to this book's Unpack Array & Group Differently example.$unwind/$group的适当使用说明,请参阅本书的展开数组并以不同方式分组示例。
3. Encourage Match Filters To Appear Early In The Pipeline鼓励匹配筛选器尽早出现
Explore If Bringing Forward A Full Match Is Possible探索是否有可能提前一场完整的匹配
As discussed, the database engine will do its best to optimise the aggregation pipeline at runtime, with a particular focus on attempting to move the 如前所述,数据库引擎将在运行时尽最大努力优化聚合管道,特别关注尝试将$match stages to the top of the pipeline. $match阶段移动到管道的顶部。Top-level 顶级$match content will form part of the filter that the engine first executes as the initial query. $match内容将构成引擎作为初始查询首先执行的筛选器的一部分。The aggregation then has the best chance of leveraging an index. 这样,聚合就有最好的机会利用指数。However, it may not always be possible to promote 但是,在不更改聚合的含义和结果输出的情况下,可能并不总是能够以这种方式推广$match filters in such a way without changing the meaning and resulting output of an aggregation.$match筛选器。
Sometimes, a 有时,稍后在管道中定义$match stage is defined later in a pipeline to perform a filter on a field that the pipeline computed in an earlier stage. $match阶段,以对管道在早期阶段计算的字段执行筛选。The computed field isn't present in the pipeline's original input collection. Some examples are:计算字段不存在于管道的原始输入集合中。例如:
-
A pipeline where a$groupstage creates a newtotalfield based on an accumulator operator.$group阶段基于累加器运算符创建新的total字段的管道。Later in the pipeline, a稍后,在管道中,$matchstage filters groups where each group'stotalis greater than1000.$match阶段筛选每个组的total大于1000的组。 -
A pipeline where a一个管道,其中$setstage computes a newtotalfield value based on adding up all the elements of an array field in each document.$set阶段根据每个文档中数组字段的所有元素相加来计算新的total字段值。Later in the pipeline, a在管道的后期,$matchstage filters documents where thetotalis less than50.$match阶段会筛选总数小于50的文档。
At first glance, it may seem like the match on the computed field is irreversibly trapped behind an earlier stage that computed the field's value. 乍一看,计算字段上的匹配似乎不可逆转地被困在计算字段值的早期阶段之后。Indeed the aggregation engine cannot automatically optimise this further. 事实上,聚合引擎无法自动进一步优化这一点。In some situations, though, there may be a missed opportunity where beneficial refactoring is possible by you, the developer.然而,在某些情况下,可能会错过开发人员可能进行有益重构的机会。
Take the following trivial example of a collection of customer order documents:以以下客户订单文档集合的琐碎示例为例:
[
{
customer_id: 'elise_smith@myemail.com',
orderdate: ISODate('2020-05-30T08:35:52.000Z'),
value: NumberDecimal('9999')
}
{
customer_id: 'elise_smith@myemail.com',
orderdate: ISODate('2020-01-13T09:32:07.000Z'),
value: NumberDecimal('10101')
}
]Let's assume the orders are in a Dollars currency, and each 假设订单是美元货币,每个值字段显示订单的value field shows the order's value in cents. value(以美分为单位)。You may have built a pipeline to display all orders where the value is greater than 100 dollars like below:您可能已经建立了一个管道来显示价值大于100美元的所有订单,如下所示:
// SUBOPTIMAL
var pipeline = [
{"$set": {
"value_dollars": {"$multiply": [0.01, "$value"]}, // Converts cents to dollars将美分转换为美元
}},
{"$unset": [
"_id",
"value",
]},
{"$match": {
"value_dollars": {"$gte": 100}, // Peforms a dollar checkPeforms a dollar check
}},
];The collection has an index defined for the 集合为value field (in cents). value字段定义了一个索引(以美分为单位)。However, the 但是,$match filter uses a computed field, value_dollars. $match筛选器使用一个计算字段value_dollars。When you view the explain plan, you will see the pipeline does not leverage the index. 当你查看解释计划时,你会看到管道没有利用指数。The $match is trapped behind the $set stage (which computes the field) and cannot be moved to the pipeline's start. $match被困在$set阶段(用于计算字段)后面,无法移动到管道的起点。MongoDB's aggregation engine tracks a field's dependencies across multiple stages in a pipeline. MongoDB的聚合引擎在管道中的多个阶段跟踪字段的依赖关系。It can establish how far up the pipeline it can promote fields without risking a change in the aggregation's behaviour. 它可以确定在不冒改变聚合行为的风险的情况下,它可以在多大程度上推广字段。In this case, it knows that if it moves the 在这种情况下,它知道如果它将$match stage ahead of the $set stage, it depends on, things will not work correctly.$match阶段移动到$set阶段之前,这取决于,事情将无法正常工作。
In this example, as a developer, you can easily make a pipeline modification that will enable this pipeline to be more optimal without changing the pipeline's intended outcome. 在本例中,作为开发人员,您可以轻松地进行管道修改,使该管道在不更改管道预期结果的情况下更加优化。Change the 将$match filter to be based on the source field value instead (greater than 10000 cents), rather than the computed field (greater than 100 dollars). $match筛选器更改为基于源字段value(大于10000美分),而不是计算字段(大于100美元)。Also, ensure the 此外,请确保$match stage appears before the $unset stage (which removes the value field). $match阶段出现在$unset阶段之前(这将删除value字段)。This change is enough to allow the pipeline to run efficiently. 此更改足以使管道高效运行。Below is how the pipeline looks after you have made this change:以下是您进行此更改后管道的外观:
// OPTIMAL
var pipeline = [
{"$set": {
"value_dollars": {"$multiply": [0.01, "$value"]},
}},
{"$match": { // Moved to before the $unset移动到$unset之前
"value": {"$gte": 10000}, // Changed to perform a cents check更改为执行美分检查
}},
{"$unset": [
"_id",
"value",
]},
];This pipeline produces the same data output. 此管道产生相同的数据输出。However, when you look at its explain plan, it shows the database engine has pushed the 然而,当您查看其解释计划时,它显示数据库引擎已将$match filter to the top of the pipeline and used an index on the value field. $match筛选器推到管道的顶部,并在值字段上使用了索引。The aggregation is now optimal because the 聚合现在是最佳的,因为$match stage is no longer "blocked" by its dependency on the computed field.$match阶段不再因其对计算字段的依赖而“阻塞”。
Explore If Bringing Forward A Partial Match Is Possible探索是否可以提前部分匹配
There may be some cases where you can't unravel a computed value in such a manner. 在某些情况下,你可能无法以这种方式解开计算值。However, it may still be possible for you to include an additional 但是,您仍然可以包含一个额外的$match stage, to perform a partial match targeting the aggregation's query cursor. $match阶段,以针对聚合的查询游标执行部分匹配。Suppose you have a pipeline that masks the values of sensitive 假设您有一个管道,它屏蔽敏感date_of_birth fields (replaced with computed masked_date fields). date_of_birth字段的值(替换为计算的masked_date字段)。The computed field adds a random number of days (one to seven) to each current date. 计算字段为每个当前日期添加随机天数(一到七天)。The pipeline already contains a 管道已包含$match stage with the filter masked_date > 01-Jan-2020. $match阶段,筛选器masked_date > 01-Jan-2020。The runtime cannot optimise this to the top of the pipeline due to the dependency on a computed value. 由于依赖于计算值,运行时无法将其优化到管道的顶部。Nevertheless, you can manually add an extra 尽管如此,您可以在管道顶部手动添加一个额外的$match stage at the top of the pipeline, with the filter date_of_birth > 25-Dec-2019. $match阶段,筛选日期为2019年12月25日。This new 这个新的$match leverages an index and filters records seven days earlier than the existing $match, but the aggregation's final output is the same. $match利用了一个索引,并在现有$match之前七天筛选记录,但聚合的最终输出是相同的。The new 新的$match may pass on a few more records than intended. $match可能会传递比预期更多的记录。However, later on, the pipeline applies the existing filter 但是,稍后,管道将应用现有的筛选器masked_date > 01-Jan-2020 that will naturally remove surviving surplus records before the pipeline completes.masked_date > 01-Jan-2020,该筛选器将在管道完成之前自然删除剩余记录。
Pipeline Match Summary管道匹配摘要
In summary, if you have a pipeline leveraging a 总之,如果你有一个利用$match stage and the explain plan shows this is not moving to the start of the pipeline, explore whether manually refactoring will help. $match阶段的管道,并且解释计划显示这并没有转移到管道的开始,那么探索手动重构是否会有所帮助。If the 如果$match filter depends on a computed value, examine if you can alter this or add an extra $match to yield a more efficient pipeline.$match筛选器依赖于计算值,请检查是否可以更改此值或添加额外的$match以产生更高效的管道。