Check MongoDB Schema with Schema Explorer
Posted on: 18/06/2018 (last updated: 28/06/2021) by Dakota KarlssonSchema Explorer makes it easy to find schema anomalies and spot data outliers in your MongoDB schema, and generate schema documentation which can be exported as a Word or CSV file. Download it here.
Are shortcuts.
One of the great things about MongoDB is that it’s schema-less, which makes adapting applications to changing requirements a breeze.
That said, data will often have a fixed implicit schema, e.g. each document in a Customers collection will likely always have a first and last name field, which makes checking that documents indeed contain certain fields a good idea.
Likewise, having the power to dynamically add new or discontinue old fields in documents can often lead to a proliferation of unwanted “versions”, which makes getting a feel for how often a certain field occurs quite helpful.
Schema Explorer provides an easy way of exploring MongoDB schema and checking its health, finding any outliers and anomalies, and visualizing data distributions.
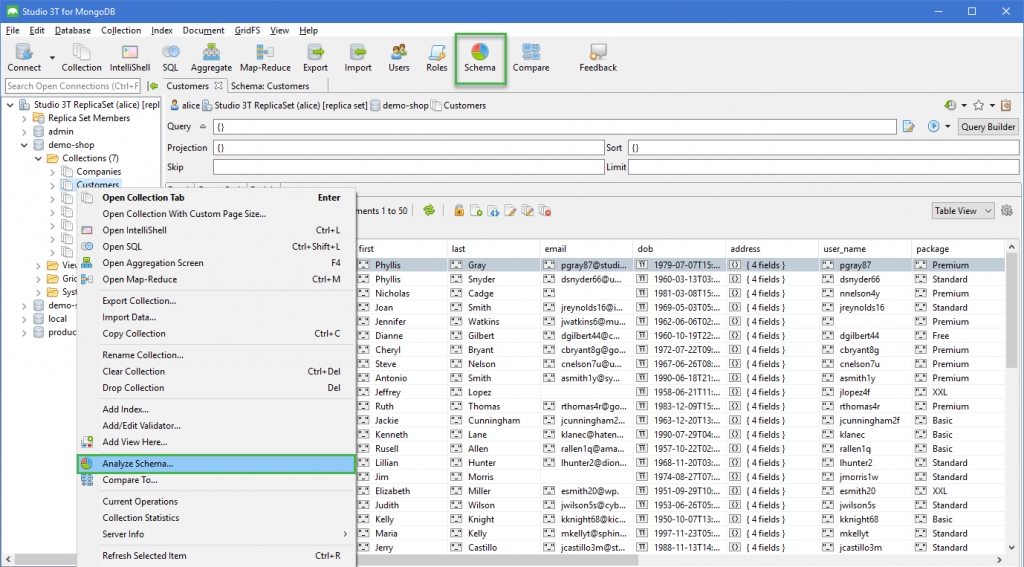
To open Schema Explorer:
- Right-click – Right-click on any connection in the Connection Tree and choose Analyze Schema
- Button – Select a collection and click on Schema in the global toolbar
In this tutorial, we’ll be using the Customers collection which can be downloaded here.
Need to update your collection’s schema altogether, before cleaning up field values? Reschema for MongoDB is a handy tool for moving an existing collection to a different collection that conforms to the schema you configure.
Configure the schema analysis
Before running the analysis, a configuration view will appear where users can set the document sample size, query criteria for the analysis, and more.
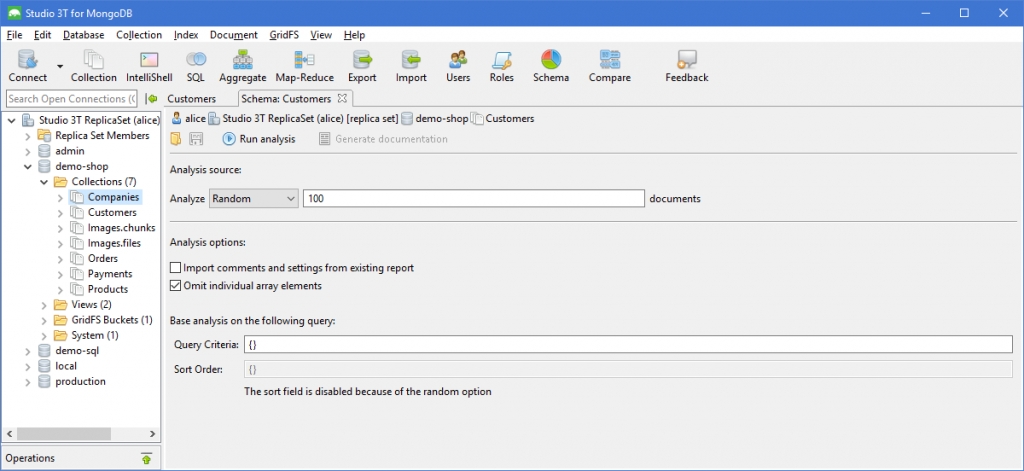
Document sample size
Under Analysis source, choose how Studio 3T should read the documents: Random, First, Last, or All. By default, Studio 3T reads the documents at random.
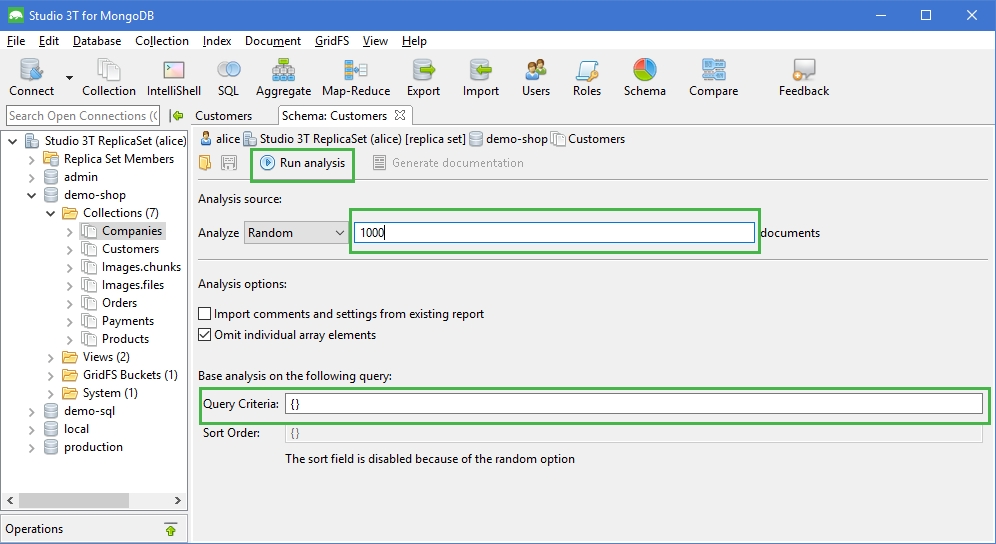
Also choose how many documents should be read for the analysis. In this tutorial, we will look at 1,000 documents.
Analysis options
Here, comments and settings from existing reports can be imported.
By default, Studio 3T will not analyze the elements of any array fields when it encounters them. This behavior can be overridden by unchecking the tick-box.
Query criteria
To filter the document sample size further, a query can be defined. In this tutorial, we will use an empty query which will return all documents in the collection.
Run the schema analysis
To run the schema analysis, click on the Run analysis button in the toolbar:
Analyze schema results
The analysis results page will show the following:
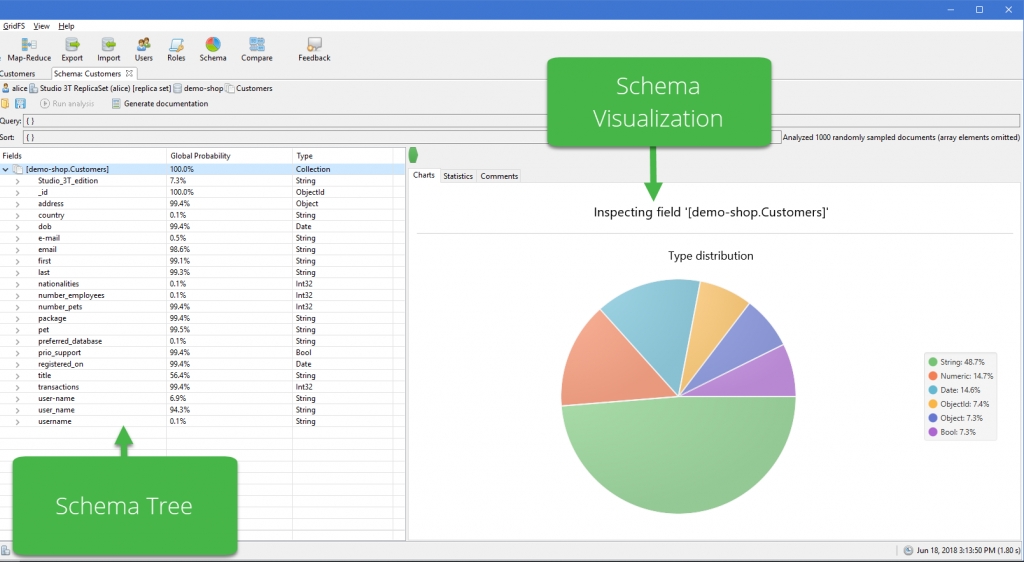
- The schema tree on the left, which shows all discovered fields, its global probability (which percentage of documents were found to contain that field), and its discovered field type(s)
- The schema visualization on the right under the Charts tab, and additional information under the Statistics and Comments tabs
Discover missing fields
The schema tree on the left shows all discovered fields, making it easy to spot documents missing crucial fields.
In our example collection Customers, we expect certain fields to be present across all documents, like first. But as the schema analysis reveals, it is only appearing in 99.1% of the fields.
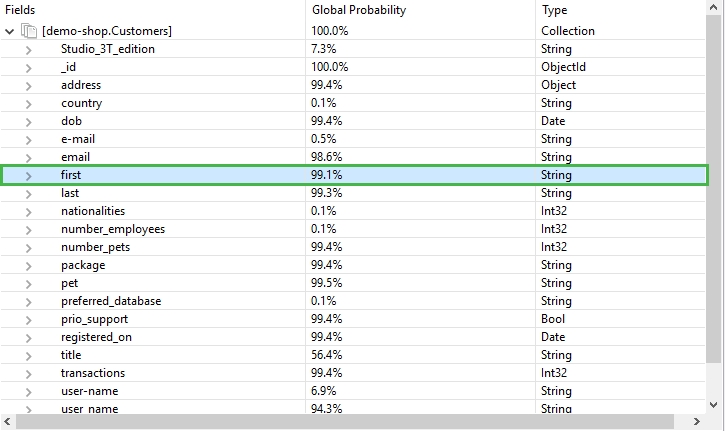
To explore documents missing a field like first:
- Right-click on the field and choose Explore documents not containing selected field
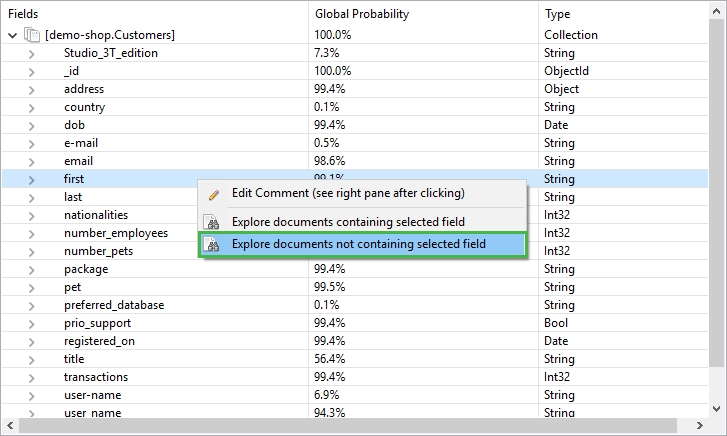
This will open a new query tab that shows all documents that do not contain the field email. It is important to note that this query will honor the base query criteria of the analysis but will bring up all matching documents in the collection, not just in the (limited) sample set.
Discover duplicates, misspellings, and other unexpected fields
Finding missing fields is just one scenario where Schema Explorer can be valuable. Another is finding unexpected fields, such as unintentional duplicates and misspellings.
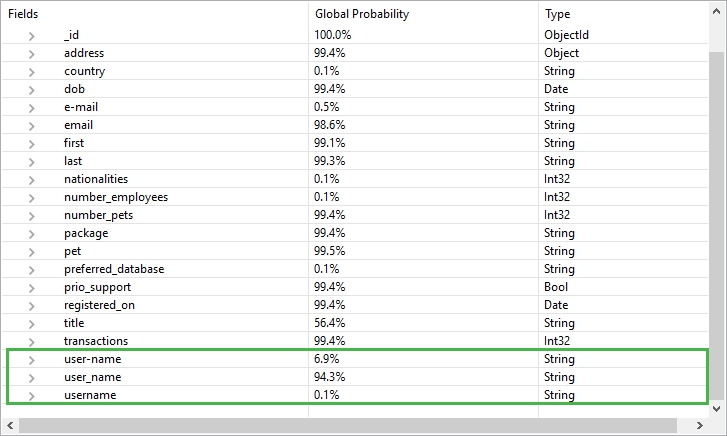
This is the case with the field user_name, which appears in around 94% of the documents, but so do two other variants: the hyphenated user-name and single word username.
Here, exploring documents containing a selected field comes in handy to easily fix the unwanted duplicates.
- Right-click on an incorrectly-spelled variant (e.g. user-name)
- Choose Explore documents containing selected field
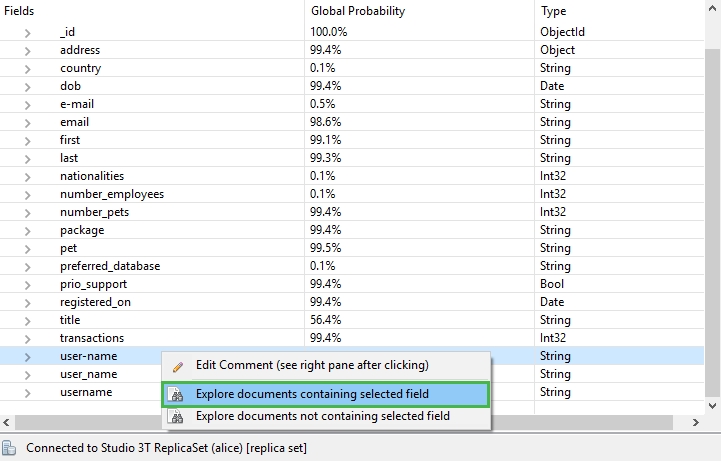
This will open a new query tab showing all documents containing the selected field (“user-name”).
- Right-click the field to rename it
- choose “All documents in collection” in the ensuing dialog to rename all occurrences in the collection:
Discover incorrect field types
Studio 3T also makes it easy to spot incorrect field types, like dates stored as string values.
In the Customers collection, the field address.street is stored as an embedded object, but the MongoDB schema analysis shows a few outliers where the field is stored as type String:
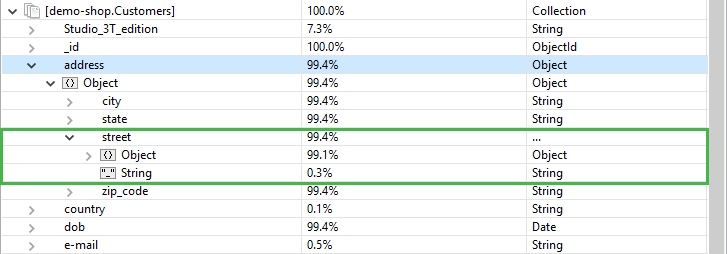
Clicking on the field shows the four incorrect entries:

To inspect the documents containing the incorrect field type:
Double-clickRight-clickDouble-click on the field
Right-click on the field and choose Explore documents with selected field of type String
Exploring data distributions
The Charts tab in Schema Explorer displays various charts depending on the data type selected.
Value histograms
For numeric fields, the Value Histogram chart shows the most frequent values found within the document set.
Looking at the field transactions, it looks like most customers have had around 50 transactions.
Top values
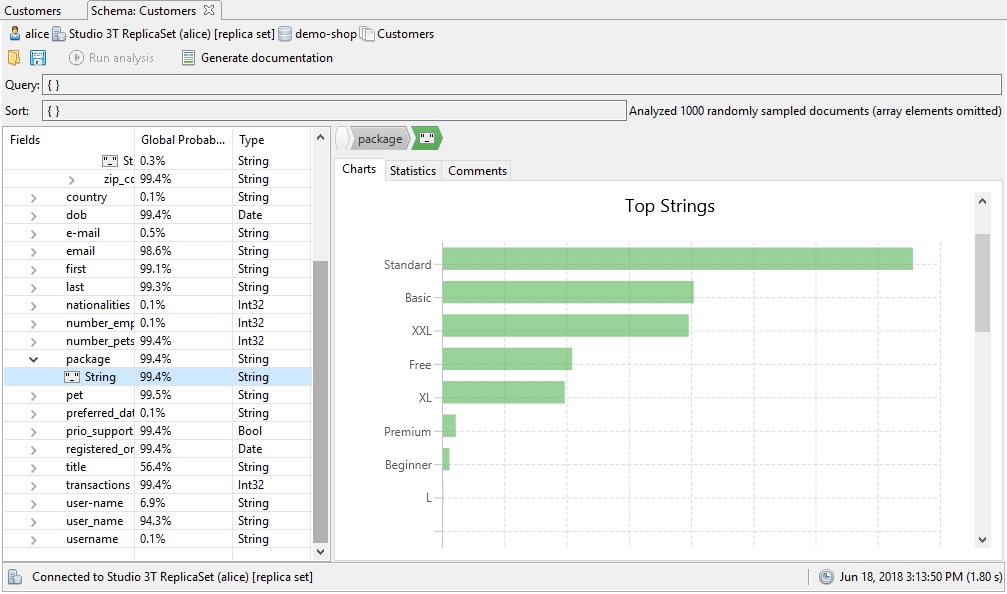
For many field types, the Top Values chart shows the top values found for that particular type across the document set.
For example, clicking on the package field – which is of type String – will show the top values (e.g. Standard), but also indicators of a potential backend glitch (e.g. Beginner).
Date distributions
For date fields, Schema Explorer shows the detailed distributions on an hourly, daily, monthly, weekly, and all-time basis.
Looking at the field registered_on and its monthly value distribution, customer registration seems to be particularly strong in the summer as well as in January, potentially a valuable insight for marketing and sales teams.
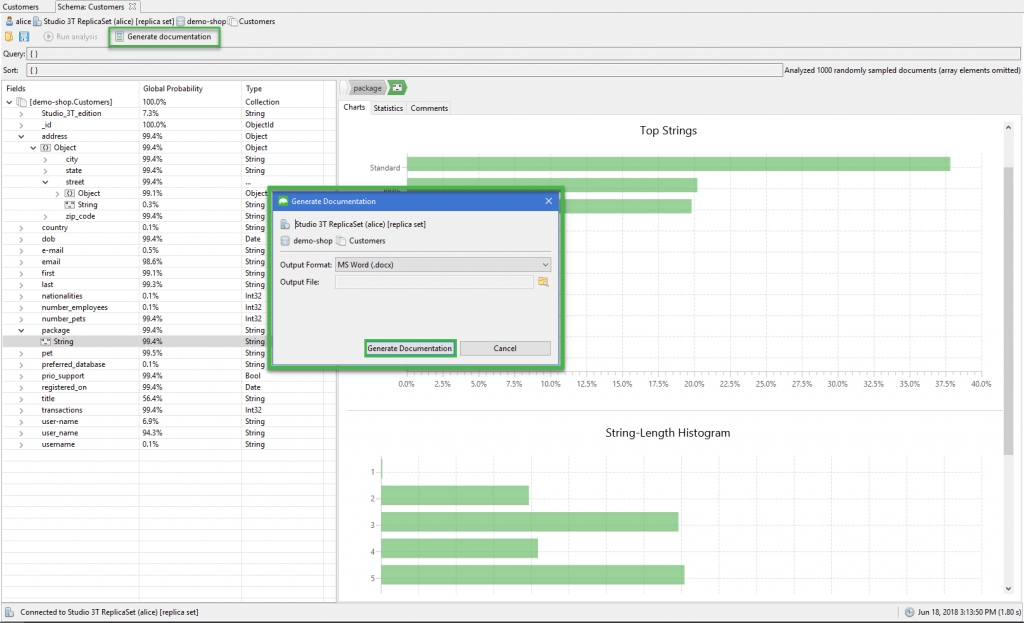
Generate documentation
The schema analysis charts and results can easily be exported to a Word or CSV file.
After running the analysis, simply click the Generate documentation button.