$densify (aggregation)
On this page本页内容
Definition定义
$densifyNew in version 5.1.5.1版新增。Creates new documents in a sequence of documents where certain values in a field are missing.在字段中缺少某些值的文档序列中创建新文档。You can use您可以使用$densifyto:$densitify来:Fill gaps in time series data.填补时间序列数据中的空白。Add missing values between groups of data.在数据组之间添加缺少的值。Populate your data with a specified range of values.使用指定的值范围填充数据。
Syntax语法
The $densify stage has this syntax:$densitify阶段具有以下语法:
{
$densify: {
field: <fieldName>,
partitionByFields: [ <field 1>, <field 2> ... <field n> ],
range: {
step: <number>,
unit: <time unit>,
bounds: < "full" || "partition" > || [ < lower bound >, < upper bound > ]
}
}
}
The $densify stage takes a document with these fields:$densitify阶段获取具有以下字段的文档:
field | field must either be all numeric values or all dates.field的值必须全部为数值或全部为日期。field continue through the pipeline unmodified.field的文档将继续通过管道,而不会被修改。<field> in an embedded document or in an array, use dot notation.<field>,请使用点表示法。field Restrictions. field限制。 | |
partitionByFields | $densify stage, each group of documents is known as a partition.$density阶段,每组文档被称为一个分区。$densify uses one partition for the entire collection.$densitify将为整个集合使用一个分区。partitionByFields Restrictions. partitionByFields限制。 | |
range | ||
range.bounds | range.bounds as either: range.bounds指定为:
bounds is an array: bounds是一个数组:
bounds is "full": bounds为"full":
bounds is "partition": bounds为"partition":
| |
range.step | field值的增量。$densifystep between the existing documents.step创建一个新文档。step must be an integer. range.unit,则step必须是整数。step can be any numeric value. step可以是任何数值。 | |
range.unit | field是日期,则为必要的。 | step字段的单位。unit as a string: unit值之一指定为字符串:
|
Behavior and Restrictions行为和限制
field Restrictions限制
For documents that contain the specified field, 对于包含指定字段的文档,$densify errors if:$density错误,如果:
Any document in the collection has a集合中的任何文档都具有日期类型的fieldvalue of type date and the unit field is not specified.field值,并且未指定unit字段。Any document in the collection has a集合中的任何文档都有一个数字类型的fieldvalue of type numeric and the unit field is specified.field值,并且指定了unit字段。Thefieldname begins with$.field名称以$开头。You must rename the field if you want to densify it.如果要使字段致密化,则必须重命名字段。To rename fields, use若要重命名字段,请使用$project.$project。
partitionByFields Restrictions限制
$densify errors if any field name in the partitionByFields array:partitionByFields数组中的任何字段名存在以下情况,则$densify出错:
Evaluates to a non-string value.计算为非字符串值。Begins with以$.$开头。
range.bounds Behavior行为
If range.bounds is an array:如果range.bounds是一个数组:
The lower bound indicates the start value for the added documents, irrespective of documents already in the collection.下限表示添加的文档的起始值,而与集合中已存在的文档无关。The lower bound is inclusive.下限包括在内。The upper bound is exclusive.上限是排他性的。$densifydoes not filter out documents with field values outside of the specified bounds.不会筛选出field值超出指定界限的文档。
Order of Output输出顺序
$densify does not guarantee sort order of the documents it outputs.不保证它输出的文档的排序顺序。
To guarantee sort order, use 要保证排序顺序,请对要排序的字段使用$sort on the field you want to sort by.$sort。
Examples实例
Densify Time Series Data稠密化时间序列数据
Create a 创建一个weather collection that contains temperature readings over four hour intervals.weather集合,其中包含四小时内的温度读数。
db.weather.insertMany( [
{
"metadata": { "sensorId": 5578, "type": "temperature" },
"timestamp": ISODate("2021-05-18T00:00:00.000Z"),
"temp": 12
},
{
"metadata": { "sensorId": 5578, "type": "temperature" },
"timestamp": ISODate("2021-05-18T04:00:00.000Z"),
"temp": 11
},
{
"metadata": { "sensorId": 5578, "type": "temperature" },
"timestamp": ISODate("2021-05-18T08:00:00.000Z"),
"temp": 11
},
{
"metadata": { "sensorId": 5578, "type": "temperature" },
"timestamp": ISODate("2021-05-18T12:00:00.000Z"),
"temp": 12
}
] )
This example uses the 此示例使用$densify stage to fill in the gaps between the four-hour intervals to achieve hourly granularity for the data points:$density阶段来填充四个小时间隔之间的间隙,以实现数据点的每小时粒度:
db.weather.aggregate( [
{
$densify: {
field: "timestamp",
range: {
step: 1,
unit: "hour",
bounds:[ ISODate("2021-05-18T00:00:00.000Z"), ISODate("2021-05-18T08:00:00.000Z") ]
}
}
}
] )
In the example:在示例中:
The$densifystage fills in the gaps of time in between the recorded temperatures.$density阶段填补了记录温度之间的时间间隔。field: "timestamp"densifies the稠密化timestampfield.timestamp字段。range:step: 1increments the将timestampfield by 1 unit.timestamp字段增加1个单位。unit: hourdensifies the按小时稠密化timestampfield by the hour.timestamp字段。bounds: [ ISODate("2021-05-18T00:00:00.000Z"), ISODate("2021-05-18T08:00:00.000Z") ]sets the range of time that is densified.设置稠密化的时间范围。
In the following output, the 在以下输出中,$densify stage fills in the gaps of time between the hours of 00:00:00 and 08:00:00.$densify阶段填充00:00:00和08:00:00之间的时间间隔。
[
{
_id: ObjectId("618c207c63056cfad0ca4309"),
metadata: { sensorId: 5578, type: 'temperature' },
timestamp: ISODate("2021-05-18T00:00:00.000Z"),
temp: 12
},
{ timestamp: ISODate("2021-05-18T01:00:00.000Z") },
{ timestamp: ISODate("2021-05-18T02:00:00.000Z") },
{ timestamp: ISODate("2021-05-18T03:00:00.000Z") },
{
_id: ObjectId("618c207c63056cfad0ca430a"),
metadata: { sensorId: 5578, type: 'temperature' },
timestamp: ISODate("2021-05-18T04:00:00.000Z"),
temp: 11
},
{ timestamp: ISODate("2021-05-18T05:00:00.000Z") },
{ timestamp: ISODate("2021-05-18T06:00:00.000Z") },
{ timestamp: ISODate("2021-05-18T07:00:00.000Z") },
{
_id: ObjectId("618c207c63056cfad0ca430b"),
metadata: { sensorId: 5578, type: 'temperature' },
timestamp: ISODate("2021-05-18T08:00:00.000Z"),
temp: 11
}
{
_id: ObjectId("618c207c63056cfad0ca430c"),
metadata: { sensorId: 5578, type: 'temperature' },
timestamp: ISODate("2021-05-18T12:00:00.000Z"),
temp: 12
}
]
Densifiction with Partitions分区稠密化
Create a 创建一个coffee collection that contains data for two varieties of coffee beans:coffee集合,其中包含两种咖啡豆的数据:
db.coffee.insertMany( [
{
"altitude": 600,
"variety": "Arabica Typica",
"score": 68.3
},
{
"altitude": 750,
"variety": "Arabica Typica",
"score": 69.5
},
{
"altitude": 950,
"variety": "Arabica Typica",
"score": 70.5
},
{
"altitude": 1250,
"variety": "Gesha",
"score": 88.15
},
{
"altitude": 1700,
"variety": "Gesha",
"score": 95.5,
"price": 1029
}
] )
Densify the Full Range of Values稠密化所有值
This example uses 本例使用$densify to densify the altitude field for each coffee variety:$densify来稠密化每个咖啡variety(品种)的altitude(海拔)字段:
db.coffee.aggregate( [
{
$densify: {
field: "altitude",
partitionByFields: [ "variety" ],
range: {
bounds: "full",
step: 200
}
}
}
] )
The example aggregation:示例聚合:
Partitions the documents by按varietyto create one grouping forArabica Typicaand one forGeshacoffee.variety对文档进行分区,为Arabica Typica和Gesha咖啡创建一个分组。Specifies a指定一个fullrange, meaning that the data is densified across the full range of existing documents for each partition.full范围,这意味着在每个分区的整个现有文档范围内对数据进行稠密化。Specifies a指定stepof200, meaning new documents are created ataltitudeintervals of200.step为200,这意味着以200的altitude间隔创建新文档。
The aggregation outputs the following documents:聚合输出以下文档:
[
{
_id: ObjectId("618c031814fbe03334480475"),
altitude: 600,
variety: 'Arabica Typica',
score: 68.3
},
{
_id: ObjectId("618c031814fbe03334480476"),
altitude: 750,
variety: 'Arabica Typica',
score: 69.5
},
{ variety: 'Arabica Typica', altitude: 800 },
{
_id: ObjectId("618c031814fbe03334480477"),
altitude: 950,
variety: 'Arabica Typica',
score: 70.5
},
{ variety: 'Gesha', altitude: 600 },
{ variety: 'Gesha', altitude: 800 },
{ variety: 'Gesha', altitude: 1000 },
{ variety: 'Gesha', altitude: 1200 },
{
_id: ObjectId("618c031814fbe03334480478"),
altitude: 1250,
variety: 'Gesha',
score: 88.15
},
{ variety: 'Gesha', altitude: 1400 },
{ variety: 'Gesha', altitude: 1600 },
{
_id: ObjectId("618c031814fbe03334480479"),
altitude: 1700,
variety: 'Gesha',
score: 95.5,
price: 1029
},
{ variety: 'Arabica Typica', altitude: 1000 },
{ variety: 'Arabica Typica', altitude: 1200 },
{ variety: 'Arabica Typica', altitude: 1400 },
{ variety: 'Arabica Typica', altitude: 1600 }
]
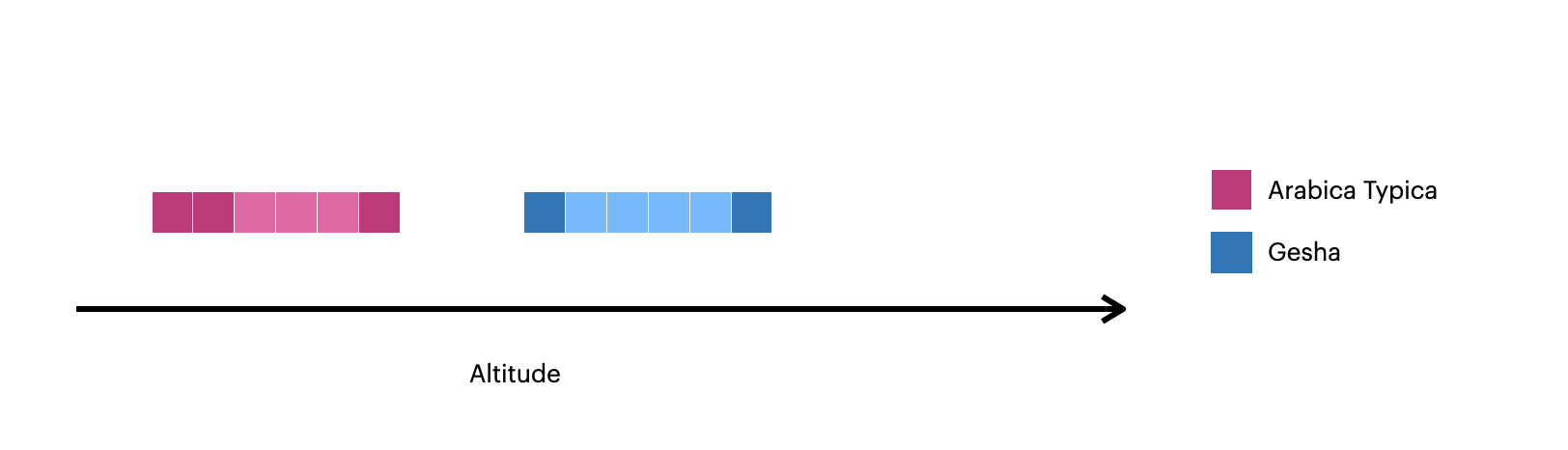
This image visualizes the documents created with 此图像将使用$densify:$density:
The darker squares represent the original documents in the collection.较暗的正方形表示集合中的原始文档。The lighter squares represent the documents created with较浅的正方形表示使用$densify.$density创建的文档。
Densify Values within Each Partition加密每个分区中的值
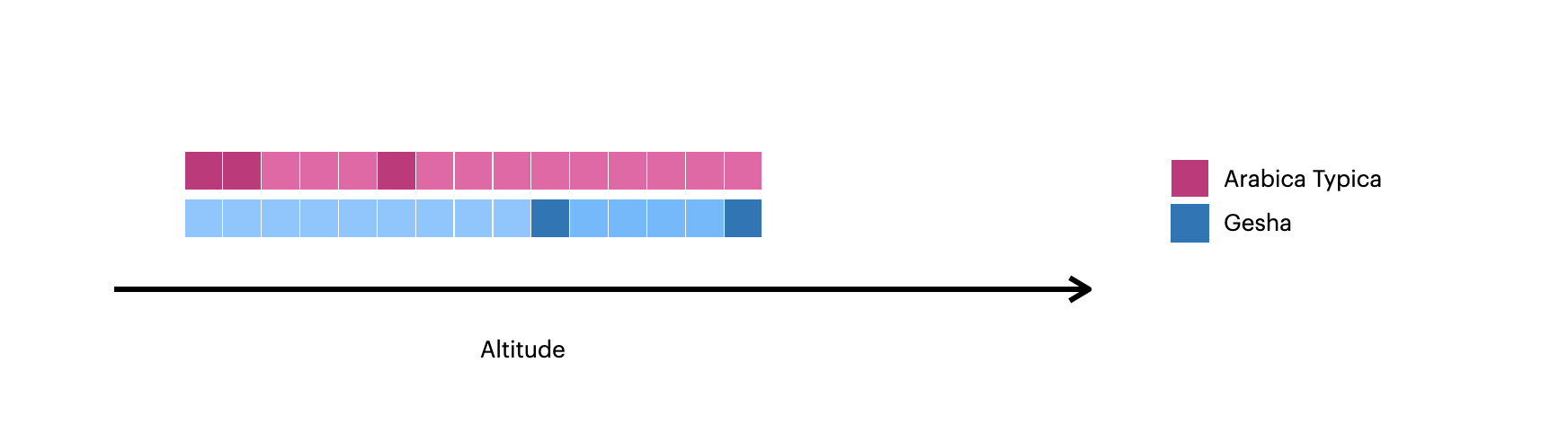
This example uses 此示例使用$densify to only densify gaps in the altitude field within each variety:$densify仅加密每个variety内altitude字段中的间隙:
db.coffee.aggregate( [
{
$densify: {
field: "altitude",
partitionByFields: [ "variety" ],
range: {
bounds: "partition",
step: 200
}
}
}
] )
The example aggregation:示例聚合:
Partitions the documents by按varietyto create one grouping forArabica Typicaand one forGeshacoffee.variety对文档进行分区,为Arabica Typica和Gesha咖啡创建一个分组。Specifies a指定partitionrange, meaning that the data is densified within each partition.partition范围,这意味着数据在每个分区内都被加密。For the对于Arabica Typicapartition, the range is600-900.Arabica Typica分区,范围为600-900。For the对于Geshapartition, the range is1250-1700.Gesha分区,范围为1250-1700。
Specifies a指定stepof200, meaning new documents are created ataltitudeintervals of200.step为200,这意味着以200的altitude间隔创建新文档。
The aggregation outputs the following documents:聚合输出以下文档:
[
{
_id: ObjectId("618c031814fbe03334480475"),
altitude: 600,
variety: 'Arabica Typica',
score: 68.3
},
{
_id: ObjectId("618c031814fbe03334480476"),
altitude: 750,
variety: 'Arabica Typica',
score: 69.5
},
{ variety: 'Arabica Typica', altitude: 800 },
{
_id: ObjectId("618c031814fbe03334480477"),
altitude: 950,
variety: 'Arabica Typica',
score: 70.5
},
{
_id: ObjectId("618c031814fbe03334480478"),
altitude: 1250,
variety: 'Gesha',
score: 88.15
},
{ variety: 'Gesha', altitude: 1450 },
{ variety: 'Gesha', altitude: 1650 },
{
_id: ObjectId("618c031814fbe03334480479"),
altitude: 1700,
variety: 'Gesha',
score: 95.5,
price: 1029
}
]
This image visualizes the documents created with 此图像将使用$densify:$densify: