When you design your schema, consider how your application needs to query and return related data. How you map relationships between data entities affects your application's performance and scalability.在设计模式时,请考虑应用程序需要如何查询和返回相关数据。如何映射数据实体之间的关系会影响应用程序的性能和可扩展性。
The recommended way to handle related data is to embed it in a sub-document. Embedding related data lets your application query the data it needs with a single read operation and avoid slow 处理相关数据的推荐方法是将其嵌入子文档中。嵌入相关数据使您的应用程序可以通过一次读取操作查询所需的数据,并避免缓慢的$lookup operations.$lookup操作。
For some use cases, you can use a reference to point to related data in a separate collection.对于某些用例,您可以使用引用指向单独集合中的相关数据。
About this Task关于此任务
To determine if you should embed related data or use references, consider the relative importance of the following goals for your application:要确定是否应该嵌入相关数据或使用引用,请考虑以下目标对您的应用程序的相对重要性:
Improve queries on related data改进对相关数据的查询If your application frequently queries one entity to return data about another entity, embed the data to avoid the need for frequent如果您的应用程序经常查询一个实体以返回另一个实体的数据,请嵌入数据以避免频繁的$lookupoperations.$lookup操作。Improve data returned from different entities改进从不同实体返回的数据If your application returns data from related entities together, embed the data in a single collection.如果您的应用程序将相关实体的数据一起返回,请将数据嵌入到单个集合中。Improve update performance提高更新性能If your application frequently updates related data, consider storing the data in its own collection and using a reference to access it.如果您的应用程序经常更新相关数据,请考虑将数据存储在自己的集合中,并使用引用访问它。When you use a reference, you reduce your application's write workload by only needing to update the data in a single place.当你使用引用时,你只需要在一个地方更新数据,就可以减少应用程序的写入工作量。
To learn more about the benefits of embedded data and references, see Embedded Data Versus References.要了解更多关于嵌入式数据和引用的好处,请参阅嵌入式数据与引用。
Before you Begin开始之前
Mapping relationships is the second step of the schema design process. Before you map relationships, identify your application's workload to determine the data it needs.映射关系是模式设计过程的第二步。在映射关系之前,请确定应用程序的工作负载,以确定它需要的数据。
Steps步骤
Identify related data in your schema识别模式中的相关数据
Identify the data that your application queries and how entities relate to each other.确定应用程序查询的数据以及实体之间的关系。
Consider the operations you identified from your application's workload in the first step of the schema design process. Note the information these operations write and return, and what information overlaps between multiple operations.考虑您在模式设计过程的第一步中从应用程序的工作负载中确定的操作。注意这些操作写入和返回的信息,以及多个操作之间重叠的信息。
Create a schema map for your related data为相关数据创建模式映射
Your schema map should show related data fields and the type of relationship between those fields (one-to-one, one-to-many, many-to-many).您的模式映射应该显示相关的数据字段以及这些字段之间的关系类型(一对一、一对多、多对多)。
Your schema map can resemble an entity-relationship model.您的模式映射可以类似于实体关系模型。
Choose whether to embed related data or use references选择是嵌入相关数据还是使用引用
The decision to embed data or use references depends on your application's common queries. Review the queries you identified in the Identify Application Workload step and use the guidelines mentioned earlier on this page to design your schema to support frequent and critical queries.嵌入数据或使用引用的决定取决于应用程序的常见查询。查看您在“识别应用程序工作负载”步骤中识别的查询,并使用本页前面提到的指南来设计您的模式,以支持频繁和关键的查询。
Configure your databases, collections, and application logic to match the approach you choose.配置您的数据库、集合和应用程序逻辑,以匹配您选择的方法。
Examples示例
Consider the following schema map for a blog application:考虑以下博客应用程序的模式映射:
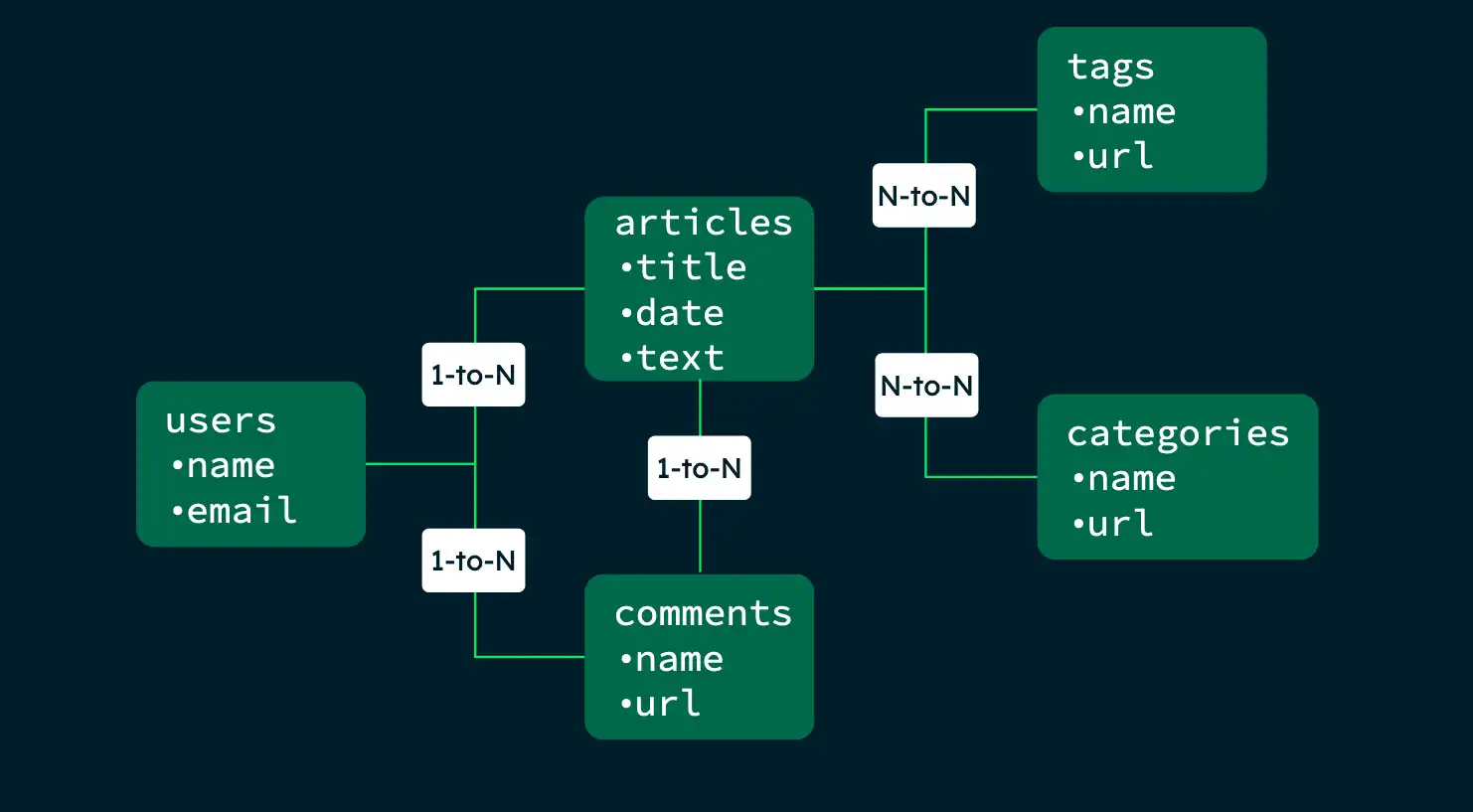
The following examples show how to optimize your schema for different queries depending on the needs of your application.以下示例显示了如何根据应用程序的需要为不同的查询优化模式。
Optimize Queries for Articles优化文章查询
If your application primarily queries articles for information such as title, embed related information in the 如果您的应用程序主要查询文章的标题等信息,请在articles collection to return all data needed by the application in a single operation.articles集合中嵌入相关信息,以便在一次操作中返回应用程序所需的所有数据。
The following document is optimized for queries on articles:以下文档针对文章查询进行了优化:
db.articles.insertOne(
{
title: "My Favorite Vacation",
date: ISODate("2023-06-02"),
text: "We spent seven days in Italy...",
tags: [
{
name: "travel",
url: "<blog-site>/tags/travel"
},
{
name: "adventure",
url: "<blog-site>/tags/adventure"
}
],
comments: [
{
name: "pedro123",
text: "Great article!"
}
],
author: {
name: "alice123",
email: "alice@mycompany.com",
avatar: "photo1.jpg"
}
}
)Optimize Queries for Articles and Authors优化文章和作者的查询
If your application returns article information and author information separately, consider storing articles and authors in separate collections. This schema design reduces the work required to return author information, and lets you return only author information without including unneeded fields.如果您的应用程序分别返回文章信息和作者信息,请考虑将文章和作者存储在单独的集合中。这种模式设计减少了返回作者信息所需的工作,并允许您仅返回作者信息,而不包括不需要的字段。
In the following schema, the 在以下模式中,articles collection contains an authorId field, which is a reference to the authors collection.articles集合包含一个authorId字段,该字段是对authors集合的引用。
Articles Collection文章集合
db.articles.insertOne(
{
title: "My Favorite Vacation",
date: ISODate("2023-06-02"),
text: "We spent seven days in Italy...",
authorId: 987,
tags: [
{
name: "travel",
url: "<blog-site>/tags/travel"
},
{
name: "adventure",
url: "<blog-site>/tags/adventure"
}
],
comments: [
{
name: "pedro345",
text: "Great article!"
}
]
}
)Authors Collection作者集合
db.authors.insertOne(
{
_id: 987,
name: "alice123",
email: "alice@mycompany.com",
avatar: "photo1.jpg"
}
)Next Steps后续步骤
After you map relationships for your application's data, the next step in the schema design process is to apply design patterns to optimize your schema. 在映射应用程序数据的关系后,模式设计过程的下一步是应用设计模式来优化模式。See Apply Design Patterns.请参见应用设计模式。