$rankFusion and $scoreFusion stages are available as Preview features. To learn more, see Preview Features.$rankFusion和$scoreFusion阶段可作为预览功能使用。要了解更多信息,请参阅预览功能。Important
$rankFusion is only available for deployments that use MongoDB 8.0 or higher.仅适用于使用MongoDB 8.0或更高版本的部署。
Definition定义
$rankFusion$rankFusionfirst executes all input pipelines independently and then de-duplicates and combines the input pipeline results into a final ranked results set.首先独立执行所有输入管道,然后去重并将输入管道结果组合成最终排名的结果集。$rankFusionoutputs a ranked set of documents based on the ranks the input documents appear in their input pipelines and the pipeline weights. This stage uses the Reciprocal Rank Fusion algorithm to rank the combined results of the input pipelines.根据输入文档在其输入管道中出现的排名和管道权重,输出一组排名的文档。该阶段使用互易秩融合算法对输入管道的组合结果进行排序。Use使用$rankFusionto search for documents in a single collection based on multiple criteria and retrieve a final ranked results set that factors in all specified criteria.$rankFusion根据多个条件在单个集合中搜索文档,并检索考虑所有指定条件的最终排名结果集。
Syntax语法
The stage has the following syntax:该阶段具有以下语法:
{ $rankFusion: {
input: {
pipelines: {
<myPipeline1>: <expression>,
<myPipeline2>: <expression>,
...
}
},
combination: {
weights: {
<myPipeline1>: <numeric expression>,
<myPipeline2>: <numeric expression>,
...
}
},
scoreDetails: <bool>
} }Command Fields命令字段
$rankFusion takes the following fields:采用以下字段:
input | $rankFusion ranks.$rankFusion排名的输入。 | |
input.pipelines |
| |
combination | input pipeline results.input管道结果。 | |
combination.weights |
| |
scoreDetails | $rankFusion computes and populates the $scoreDetails metadata field for each output document. false。指定$rankFusion是否为每个输出文档计算并填充$scoreDetails元数据字段。scoreDetails。 |
Behavior行为
Collections集合
You can only use 您只能将$rankFusion with a single collection. You cannot use this aggregation stage at a database scope.$rankFusion用于单个集合。您不能在数据库范围内使用此聚合阶段。
De-Duplication删除功能
$rankFusion de-duplicates the results across multiple input pipelines in the final output. Each unique input document appears at most once in the $rankFusion output, regardless of the number of times that the document appears in input pipeline outputs.$rankFusion在最终输出中消除了多个输入管道中的重复结果。每个唯一的输入文档在$rankFusion输出中最多出现一次,而不管该文档在输入管道输出中出现的次数。
Input Pipelines输入管道
Each 每个input pipeline must be both a Selection Pipeline and a Ranked Pipeline.input管道都必须是选择管道和分级管道。
Selection Pipeline选择管道
A Selection Pipeline retrieves a set of documents from a collection without performing any modifications after retrieval. 选择管道从集合中检索一组文档,检索后不进行任何修改。$rankFusion compares documents across different input pipelines which requires that all input pipelines output the same unmodified documents.$rankFusion比较不同输入管道中的文档,这要求所有输入管道输出相同的未修改文档。
Note
If you want to modify the documents that you search for with 如果要修改使用$rankFusion, perform those modifications after the $rankFusion stage.$rankFusion搜索的文档,请在$rankFusions阶段后执行这些修改。
A selection pipeline must only contain the following stages:选择管道必须仅包含以下阶段:
| |
Ranked Pipeline分级管道
A ranked pipeline sorts or orders documents. 排序管道对文档进行排序或排序。$rankFusion uses the order of ranked pipeline results to influence the output ranking. Ranked pipelines must meet one of the following criteria:$rankFusion使用排名管道结果的顺序来影响输出排名。分级管道必须符合以下标准之一:
Input Pipeline Names输入管道名称
Pipeline names in input must meet the following restrictions:input中的管道名称必须满足以下限制:
Must not be an empty string不能为空字符串Must not start with a不得以$$开头Must not contain the ASCII null character delimiter字符串中任何地方都不能包含ASCII空字符分隔符\0anywhere in the string\0Must not contain a不允许包含.
Reciprocal Rank Fusion (RRF) Formula互易秩融合(RRF)公式
$rankFusion orders results according to the Reciprocal Rank Fusion (RRF) Formula. This stage places the RRF score for each document in the 根据互易秩融合(RRF)公式对结果进行排序。此阶段将每个文档的RRF分数放置在输出结果的score metadata field of the output results. The RRF formula ranks documents with a combination of the following factors:score元数据字段中。RRF公式结合以下因素对文档进行排名:
The placement of documents in input pipeline results在输入管道结果中放置文档The number of times that a document appears in different input pipelines文档在不同输入管道中出现的次数The输入管道的weightsof input pipelines.weights(权重)。
For example, if a document has a high ranking in multiple pipeline result sets, the RRF score for that document would be higher than if that same document has the same ranking in some input pipelines, but is not present (or has a lower ranking) in the other pipelines例如,如果一个文档在多个管道结果集中排名很高,则该文档的RRF得分将高于同一文档在某些输入管道中排名相同,但在其他管道中不存在(或排名较低)的情况
The Reciprocal Rank Fusion (RRF) Formula is equivalent to the following algebraic operation:互易秩融合(RRF)公式等价于以下代数运算:
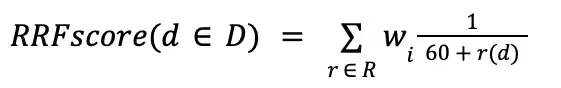
Note
In this formula, 60 is a sensitivity parameter that MongoDB determined.在这个公式中,60是MongoDB确定的敏感度参数。
The below table contains the variables that the RRF formula uses:下表包含RRF公式使用的变量:
| D | |
| d | |
| R | d appears in.d出现在中的输入管道的排名集。 |
| r(d) | d in this input pipeline.d在此输入管道中的排名。 |
| w | d appears in.d所在的输入管道的权重。 |
Each term in the summation represents the appearance of a document 求和中的每个项都表示文档d in one of the input pipelines. The total RRF score for d is the summation of each of these terms across all the input pipelines that d appears in.d在其中一个input管道中的出现。d的RRF总得分是d出现的所有输入管道中每个项的总和。
RRF Calculation ExampleRRF计算示例
Consider a 考虑一个$rankFusion pipeline stage with one $search and one $vectorSearch input pipeline.$rankFusion管道阶段,其中有一个$search和一个$vectorSearch输入管道。
All input pipelines output the same 3 documents: 所有输入管道输出相同的3个文档:Document1, Document2, and Document3.Document1、Document2和Document3。
The $search pipeline ranks the documents in the following order:$search管道按以下顺序对文档进行排序:
Document3Document2Document1
The $vectorSearch pipeline ranks the documents in the following order:$vectorSearch管道按以下顺序对文档进行排序:
Document1Document2Document3.
rankFusion computes the RRF score for 通过以下操作计算Document1 through the following operation:Document1的RRF分数:
RRFscore(Document1) = 1/(60 + search_rank_of_Document1) + (1/(60 + vectorSearch_rank_of_Document1))
RRFscore(Document1) = 1/63 + 1/61
RRFscore(Document1) = 0.0322664585The score metadata field for Document1 is 0.0322664585.Document1的score元数据字段为0.0322664585。
scoreDetails
If you set 如果将scoreDetails to true, $rankFusion creates a scoreDetails metadata field for each document. The scoreDetails field contains information about the final ranking.scoreDetails设置为true,$rankFusion将为每个文档创建一个scoreDetails元数据字段。scoreDetails字段包含有关最终排名的信息。
Note
When you set 当您将scoreDetails to true, $rankFusion sets the scoreDetails metadata field for each document but does not automatically output the scoreDetails metafield.scoreDetails设置为true时,$rankFusion会为每个文档设置scoreDetails元数据字段,但不会自动输出scoreDetails图元字段。
To view the 要查看scoreDetails metadata field, you must either:scoreDetails元数据字段,您必须:
use a在$projectstage after$rankFusionto project thescoreDetailsfield$rankFusion之后使用$project阶段来投影scoreDetails字段use a在$addFieldsstage after$rankFusionto add thescoreDetailsfield to your pipeline output$rankFusion之后使用$addFields阶段将scoreDetails字段添加到管道输出中
The scoreDetails field contains the following subfields:scoreDetails字段包含以下子字段:
value | |
description | $rankFusion computed the RRF score.$rankFusion如何计算RRF分数。 |
details |
Each array entry in the details field contains the following subfields:details字段中的每个数组条目都包含以下子字段:
inputPipelineName | |
rank | N/A in a pipeline stage output if a document that is returned in other pipeline stage output is not present in this pipeline stage's output.N/A。 |
weight | |
value | { $meta: 'score' } for this document, value contains { $meta: 'score' }.{ $meta: 'score' },则value包含{ $meta: 'score' }。 |
description | description field as part of the scoreDetails for this document, details.description contains that field value.description字段作为此文档的scoreDetails的一部分,则details.description包含该字段值。 |
details | scoreDetails field of the input pipeline. If the input pipeline does not output a scoreDetails field, this field is an empty array.scoreDetails字段。如果输入管道不输出scoreDetails字段,则此字段为空数组。 |
Warning
MongoDB does not guarantee any specific output format for MongoDB不保证scoreDetails.scoreDetails的任何特定输出格式。
For example, the following code blocks shows the 例如,以下代码块显示了具有scoreDetails field for a $rankFusion operation with $search, $vectorSearch, and $match input pipelines:$search、$vectorSearch和$match输入管道的$rankFusion操作的scoreDetails字段:
{
value: 0.030621785881252923,
description: "value output by reciprocal rank fusion algorithm, computed as sum of weight * (1 / (60 + rank)) across input pipelines from which this document is output, from:"
details: [
{
inputPipelineName: 'search',
rank: 2,
weight: 1,
value: 0.3876491287,
description: "sum of:",
details: [... omitted for brevity in this example ...]
},
{
inputPipelineName: 'vector',
rank: 9,
weight: 3,
value: 0.7793490886688232,
details: [ ]
},
{
inputPipelineName: 'match',
rank: 10,
weight: 1,
details: []
}
]
}Explain Results解释结果
MongoDB converts MongoDB将$rankFusion operations into a set of existing aggregation stages that, in combination, compute the output result prior to query execution. $rankFusion操作转换为一组现有的聚合阶段,这些阶段结合在一起,在查询执行之前计算输出结果。The Explain Results for a $rankFusion operation show the full execution of the underlying aggregation stages that $rankFusion uses to compose the final result.$rankFusion操作的“解释结果”显示了$rankFusion用于组合最终结果的底层聚合阶段的完整执行情况。
Examples示例
MongoDB Shell
This example uses a collection with embeddings and text fields. Create 此示例使用具有嵌入和文本字段的集合。在集合上创建search and vectorSearch type indexes on the collection.search和vectorSearch类型索引。
The following index definition automatically indexes all the dynamically indexable fields in the collection for running 以下索引定义自动为集合中的所有动态可索引字段建立索引,以便对索引字段运行$search queries against the indexed fields.$search查询。
search Index搜索索引
db.embedded_movies.createSearchIndex(
"search_index",
{
mappings: { dynamic: true }
}
)The following index definition indexes the field with the embeddings in the collection for running 以下索引定义使用集合中的嵌入对字段进行索引,以便对该字段运行$vectorSearch queries against that field.$vectorSearch查询。
vectorSearch Index矢量搜索索引
db.embedded_movies.createSearchIndex(
"vector_index",
"vectorSearch",
{
"fields": [
{
"type": "vector",
"path": "<FIELD_NAME>",
"numDimensions": <NUMBER_OF_DIMENSIONS>,
"similarity": "dotProduct"
}
]
}
);The following aggregation pipeline uses 以下聚合管道使用$rankFusion with the following input pipelines:$rankFusion和以下输入管道:
searchOne | 20 | vector type for the term specified as embeddings. The query considers up to 500 nearest neighbors, but limits the results to 20 documents.vector类型索引的字段运行向量搜索。查询最多考虑500个最近邻,但将结果限制在20个文档内。 |
searchTwo | 20 |
db.embedded_movies.aggregate( [
{
$rankFusion: {
input: {
pipelines: {
searchOne: [
{
"$vectorSearch": {
"index": "<INDEX_NAME>",
"path": "<FIELD_NAME>",
"queryVector": <QUERY_EMBEDDINGS>,
"numCandidates": 500,
"limit": 20
}
}
],
searchTwo: [
{
"$search": {
"index": "<INDEX_NAME>",
"text": {
"query": "<QUERY_TERM>",
"path": "<FIELD_NAME>"
}
}
},
{ "$limit": 20 }
],
}
}
}
},
{ $limit: 20 }
] )This operation performs the following actions:此操作执行以下操作:
Executes the执行inputpipelinesinput管道Combines the returned results合并返回的结果Outputs the first 20 documents which are the top 20 ranked results of the输出前20个文档,这些文档是$rankFusionpipeline$rankFusion管道排名前20的结果
Node.js
The Node.js examples on this page use the 本页上的Node.js示例使用Atlas示例数据集中的sample_mflix database from the Atlas sample datasets. sample_mflix数据库。To learn how to create a free MongoDB Atlas cluster and load the sample datasets, see Get Started in the MongoDB Node.js driver documentation.要了解如何创建免费的MongoDB Atlas集群并加载示例数据集,请参阅MongoDB Node.js驱动程序文档中的入门。
To use the MongoDB Node.js driver to add a 要使用MongoDB Node.js驱动程序将$rankFusion stage to an aggregation pipeline, use the $rankFusion operator in a pipeline object.$rankFusion阶段添加到聚合管道中,请在管道对象中使用$rankFusion运算符。
Before running the following example, you must create an Atlas Search index named 在运行以下示例之前,您必须创建一个名为default. Include the following code in your application to create a search index on the movies collection:default的Atlas搜索索引。在应用程序中包含以下代码,以创建电影集合的搜索索引:
const index = {
name: "default",
definition: {
mappings: { dynamic: true }
}
}
const result = collection.createSearchIndex(index);The following example creates a pipeline stage that executes two pipelines, 以下示例创建了一个管道阶段,该阶段执行两个管道searchPlot and searchGenre, that perform $search operations by using the default search index. searchPlot和searchGenre,这两个管道使用默认搜索索引执行$search操作。The $rankFusion stage then ranks the search results based on each $search pipeline's assigned weight and returns the ordered results. $rankFusion阶段然后根据每个$search管道的分配权重对搜索结果进行排名,并返回排序结果。The $addFields stage includes the scoreDetails field in the return documents. The example then runs the aggregation pipeline:$addFields阶段包括退货文档中的scoreDetails字段。然后,该示例运行聚合管道:
const pipeline = [
{
$rankFusion: {
input: {
pipelines: {
searchPlot: [
{
$search: {
index: "default",
text: { query: "space", path: "plot"}
}
}
],
searchGenre: [
{
$search: {
index: "default",
text: { query: "adventure", path: "genres" }
}
}
]
}
},
combination: { weights: {searchPlot: 0.6, searchGenre: 0.4} },
scoreDetails: true
}
},
{ $addFields: { scoreDetails: { $meta: "searchScoreDetails" } } }
];
const cursor = collection.aggregate(pipeline);
return cursor;